Hey all,
It's a new season here at Fly.io! Well, it's a new season for everyone, but our internal alarm has gone off, reminding us that it's been a couple of months since we last told you about what we've been up to.
So let's do that! Here we go.
Product updates
We update the Fresh Produce section of our Community forum with changelogs about what's happening on the platform. Right now, it might as well be called "Fresh MPG" because our managed Postgres offering has gotten a swift glow-up:- We now have a "Starter" plan for MPG, clocking in at $72/month. (Folks wanted something in between the Basic $38 level and the $282 Launch level. A reasonable ask!)
- Speaking of MPG, we now have additional region support, some snazzy metrics and a built-in extensions page.
- Your MPG cluster's storage can now auto-expand past 500GB (up to 1Tb!), and there's also a proxy that lets you connect to it from the internet.
Inside Flyball
- We're (still) hiring! If you're a fullstack or platform engineer, check out our job listings over here.
-
A couple of updates from the Support side of the house: you can now respond to support threads from your Dashboard and also upgrade your Support plan by clicking a button.
Feature story: LVM is dead, long live LVM!
The first version of Fly volumes was built on top of LVM2 (Linux Volume Manager). It gave us a reliable way to spin up new block devices that Fly machines could attach and mount. Snapshots were easy too, which made daily backups straightforward. Even resizing a volume was just a simple lvextend. Then two (well, maybe three) things happened. First: We switched machine root devices from a single writeable block device to an overlay setup. The idea was simple: the base layer is a read-only application image shared by many machines, even served over the network. On top of it, every machine gets a fresh, disposable, writeable layer on boot. If you needed permanent state, you had to put it on a Fly volume. Second: Linux swap moved from being a file on the root filesystem to its own block device, which also gets reset on every start. Third: Volume forking and machine migrations became a thing. That meant not only more volumes but also point-in-time snapshots to hydrate remote volumes. LVM2 could do all of this, but it didn't scale. Once we hit around 1k devices, lock contention spiked, system load shot through the roof, and servers started lagging out. Fast forward to the AI era: the biggest sandbox (agent? machine?) customers started launching thousands of machines and churning through thousands of volumes and forks as fast as possible. LVM2 just wasn't keeping up. It's not that LVM2 is bad. Indeed, it's rock-solid. But you pay for that reliability. The most painful part? Every lvcreate, lvremove, or lvanything run scans all devices and grabs a global lock. The more devices, the longer the scan, and the longer everyone else has to wait. We tried a bunch of tricks to cut contention, like running read-only where possible, filtering which devices got scanned, and more. But the reality was: LVM2 does way more than we actually need. Our main use case boils down to a thin volume pool and lots of ephemeral block devices that might be used once and should be disposable at speed. Underneath, LVM2 just wraps Linux device-mapper thin provisioning with a nice interface abstraction and a pile of bookkeeping to keep everything consistent. In fact, LVM2 keeps multiple copies of its metadata. Usually one at the start of each physical volume, plus plain-text backups under /etc/lvm/backup. The format is human-readable, so you can crack it open and inspect it without special tools. We set a course to replace it It turns out that adding and removing thin devices with device-mapper directly is super fast. It rarely fails, and when retries are done properly they are idempotent. The hard part is the metadata bookkeeping and making sure concurrency never eats anyone's data. Easy, right? A device-mapper thin pool always needs two block devices: - a data device to store the actual blocks - a metadata device to keep track of which blocks belong to which thin device The thin-pool metadata is managed by the device-mapper kernel driver. It survives reboots, but it only knows about thin IDs (simple integers) and the block mappings tied to them. It does not store names, volume sizes, or any higher-level properties. Those details have to be persisted somewhere else, which is exactly what LVM2 does. Our choice? SQLite. We love it. For hosts that were struggling with LVM lock contention, the impact was huge. Faster device-pool operations also meant faster machine start times. Here's a graph from the moment we rolled it out on a busy system. Can you spot the latency drop?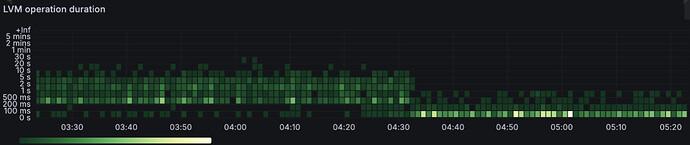
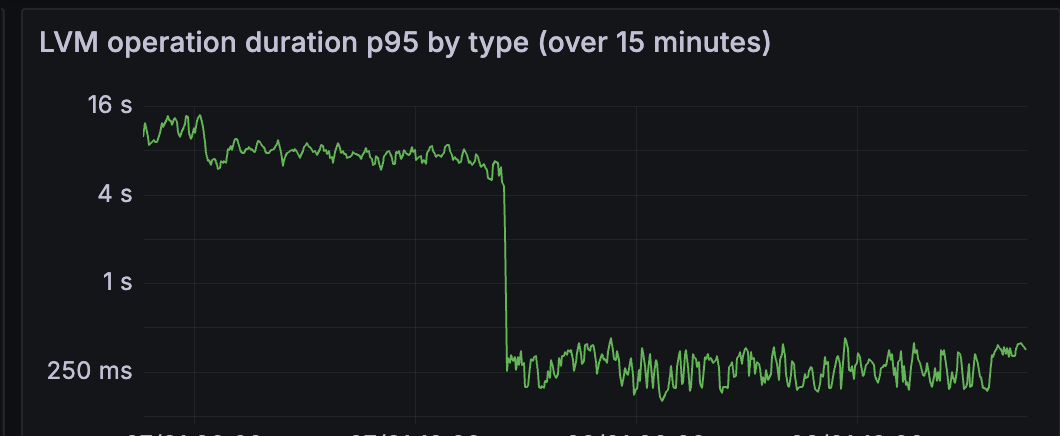 Not only that, today we have hosts handling 3,000 to 5,000 devices and they haven't blinked once.
And that's it for us this time! As always, we want to hear from you, so please say hello if there's something we can help you with or some feedback you want to share.
Thanks,
The Fly.io Team
Not only that, today we have hosts handling 3,000 to 5,000 devices and they haven't blinked once.
And that's it for us this time! As always, we want to hear from you, so please say hello if there's something we can help you with or some feedback you want to share.
Thanks,
The Fly.io Team